132 private links
To make note taking using LaTeX viable, I had four goals in mind:
- Writing text and mathematical formulas in LaTeX should be as fast as the lecturer writing on a blackboard: no delay is acceptable.
- Drawing figures should be almost as fast as the lecturer.
- Managing notes, i.e. adding a note, compiling all my notes, compiling the last two lectures, searching in notes, etc. should be easy and quick.
- Annotating pdf documents using LaTeX should be possible for when I want to write notes alongside a pdf document.
This blog post will focus on the first item: writing LaTeX.

Firefox Send, send.firefox.com, is a free encrypted file transfer service that allows users to safely and simply share files from any browser.
In exchange for free mails, would you let your postman open your letters, read them, and insert ads related to their contents?
I am a bit dissatisfied with the use of the Tragedy of the commons to represent issues with free and open source software development. It is not an abstract resource that can be depleted when overused. It is not magically maintained if left alone.
It is based on the work of people, and we should not erase those people.
Unfortunately (and it is by design), most of the licences and the vocabulary around it are focused on the software’s user. After all, they work by reducing the creator’s right to empower the user.
As examples of this vocabulary, we have the distinction between “free as in beer” and “free as in speech” to show that the “free” word in “free software” has more to do with freedom and people’s rights to use, study, modify and share a program, than its actual price. Although, in practice, the overwhelming majority of FOSS will not cost you anything.
The author tried to edit data in spreadsheet programs.
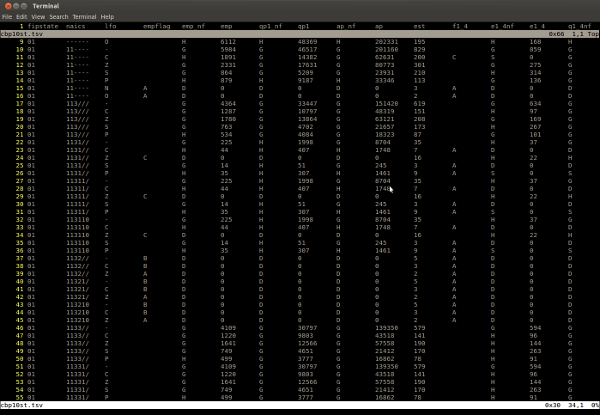
This post illustrate ho to use Vim to edit tabular data, although there are a few things that will make it more pleasant. It is assumed that editing files are in tab-separated value format (TSV).
"But what about CSV files?" Just. Don't.
Do: convert your CSV to TSV and back for editing.
When it comes to using computers to steal money, few can come close to matching the success of Russian hacker Evgeniy Bogachev.
The $3 million bounty the FBI has offered for Bogachev’s capture is larger than any that has ever been offered for a cybercriminal—but that sum represents only a tiny fraction of the money he has stolen through his botnet GameOver ZeuS.1 At its height in 2012 and 2013, GameOver ZeuS, or GOZ, comprised between 500,000 and 1 million compromised computers all over the world that Bogachev could control remotely. For years, Bogachev used these machines to spread malware that allowed him to steal banking credentials and perpetrate online extortion.2 No one knows exactly how much money Bogachev stole from his thousands of victims using GOZ, but the FBI conservatively estimates that it was well over $100 million.
A list of things to pay attention to when making interviews.
The list enters some few items in details, while it only lists other items without explanation.
When I think about who I would like to work with as a programmer, I think so much more about non-technical skills than technical skills that make somebody a good co-worker. In fact, all of the skills that are in this post contribute to writing good code that improves technical projects. Most of them are really helpful for careers outside of programming too, but I'm going to focus on why they're useful for programmers specifically.
In The War of Art and Turning Pro, Steven Pressfield talks about “The Resistance” that keeps us from doing our work.
If you’re a maker and you’ve yet to read these two books, do yourself a favor and buy them today.

Most widely-used programming languages have at least one regular conference dedicated to discussing it. Heck, even Lisp has one. It’s a place to talk about the latest developments of the language, recent and upcoming standards, and so on.
However, C is a notable exception. Despite its role as the foundation of the entire software ecosystem, there aren’t any regular conferences about C. I have a couple of theories about why.
From Josh Mcguigan.
This is a tutorial on building your own shell using Rust, in the spirit of the build-your-own-x list. Creating a shell is a great way to understand how the shell, terminal emulator, and OS work together.
In early tests, this laser-activated silk and gold material held wounds together better than stitches or glue.
Alpine Linux-based Docker images are small, but they can still bloat up quickly. If you're concerned about image size, search for alternatives, like Minideb.
When the Docker revolution started, one argument among many in favor of using containers instead of virtual machines was their size. Container images were supposed to be small.
However, several anti-patterns quickly emerged in the early days of Docker. First, most people wanted to treat containers just like VMs, hence they wanted an SSH server in them, they wanted to run multiple processes in them and they wanted their regular Linux distributions.
This quickly ballooned the size of Docker images that could be pulled from the Docker Hub. Official Ubuntu and CentOS images used to be above 600 MB. Once dependencies and application code got added, it was not rare to see several GB Docker images around.

You will learn in this post how to:
- decompose double-seasonal time series
- detrend time series
- model and forecast double-seasonal time series with trend
- use two types of simple regression trees
- set important hyperparameters related to regression tree
Rust is an imperative systems programming language. Why does it have so much attention from functional programming advocates? Is it hiding a functional nature?
For the longest time I did not know what everything meant in htop.
I thought that load average 1.0 on my two core machine means that the CPU usage is at 50%. That's not quite right. And also, why does it say 1.0?
I decided to look everything up and document it here.
They also say that the best way to learn something is to try to teach it.
A nice blog post about Delaunay triangulation and Voronoi tessellation of a sphere.
Very nice interactive JavaScript animation that shows the triangulation and the tessellation as a function of some paramenters.

Marker is a command bookmark manager for the console. The tool lets you bookmark commands and command templates, and easily retrieve them using a real-time fuzzy matcher.
The tool is useful to remember commands used previously, which is like going through your Bash history but better since you can add descriptions for each bookmark (and add placeholders), as well as to save some commands you come across, for future use. Your command bookmarks are saved in a text file located in ~/.local/share/marker/.
Marker features include:
- Real-time fuzzy matcher for commands and descriptions, with a UI selector to easily choose the desired command if more than one is presented
- Command template: You can bookmark commands with placeholders and quickly place the cursor at those placeholders using a keyboard shortcut
- Includes common commands for Linux and macOS from the tldr project
- Keyboard shortcuts: Ctrl + space to search for commands, Ctrl + k to bookmark a command, and Ctrl + t to place the cursor at the next placeholder, identified by '{{anything}}', to fill out the command - these are customizable
Keeping track of your work hours will give you an insight about the amount of work you get done in a specific time frame. There are plenty of GUI-based productivity tools available on the Internet for tracking work hours. However, I couldn’t find a good CLI-based tool. Today, I stumbled upon a a simple, yet useful tool named “Moro” for tracking work hours.
Moro is a Finnish word which means “Hello”. Using Moro, you can find how much time you take to complete a specific task. It is free, open source and written using NodeJS.