134 private links


View colored, incremental diff in workspace or from stdin with side by side and auto pager support (was "cdiff").
GNU recutils is a set of tools and libraries to access human-editable, text-based databases called recfiles. The data is stored as a sequence of records, each record containing an arbitrary number of named fields. Advanced capabilities usually found in other data storage systems are supported: data types, data integrity (keys, mandatory fields, etc.) as well as the ability of records to refer to other records (sort of foreign keys). Despite its simplicity, recfiles can be used to store medium-sized databases.
Parsr, is a minimal-footprint document (image, pdf) cleaning, parsing and extraction toolchain which generates readily available, organized and usable data for data scientists and developers.
It provides users with clean structured and label-enriched information set for ready-to-use applications ranging from data entry and document analysis automation, archival, and many others.
Currently, Parsr can perform:
- Document Hierarchy Regeneration - Words, Lines and Paragraphs
- Headings Detection
- Table Detection and Reconstruction
- Lists Detection
- Text Order Detection
- Named Entity Recognition (Dates, Percentages, etc)
- Key-Value Pair Detection (for the extraction of specific form-based entries)
- Page Number Detection
- Header-Footer Detection
- Link Detection
- Whitespace Removal
Provides an implementation of today's most used tokenizers, with a focus on performance and versatility.
Main features:
- Train new vocabularies and tokenize, using today's most used tokenizers.
- Extremely fast (both training and tokenization), thanks to the Rust implementation. Takes less than 20 seconds to tokenize a GB of text on a server's CPU.
- Easy to use, but also extremely versatile.
- Designed for research and production.
- Normalization comes with alignments tracking. It's always possible to get the part of the original sentence that corresponds to a given token.
- Does all the pre-processing: Truncate, Pad, add the special tokens your model needs.
information theory, linguistics and computer science, the Levenshtein distance is a string metric for measuring the difference between two sequences. Informally, the Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions or substitutions) required to change one word into the other.
Homer, a text analyser in Python, can help make your text more clear, simple and useful for your readers.
peco is a CLI utility that filters text interactively. The tool is written in the Go programming language. It's free and open source software.
In order to successfully work with the Linux sed editor and the awk command in your shell scripts, you have to understand regular expressions or in short regex. Since there are many engines for regex, we will use the shell regex and see the bash power in working with regex.
First, we need to understand what regex is, then we will see how to use it.
Table of contents include:
What is regex, Types of regex, Define BRE Patterns, Special Characters, Anchor Characters, The dot Character, Character Classes, Negating Character Classes, Using Ranges, Special Character Classes, The Asterisk, Extended Regular Expressions, The question mark, The Plus Sign, Curly Braces, Pipe Symbol, Grouping Expressions, Practical examples, Counting Directory Files, Validating E-mail Address.
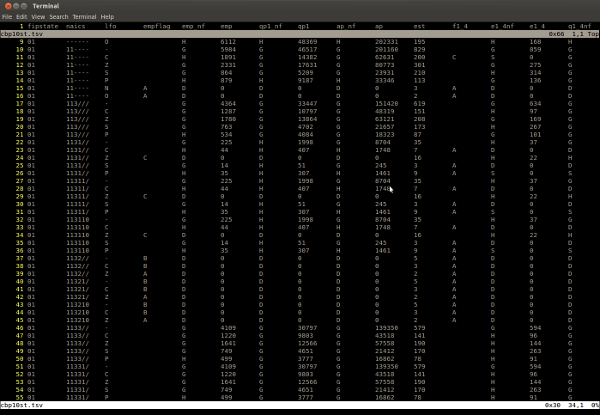
The author tried to edit data in spreadsheet programs.
This post illustrate ho to use Vim to edit tabular data, although there are a few things that will make it more pleasant. It is assumed that editing files are in tab-separated value format (TSV).
"But what about CSV files?" Just. Don't.
Do: convert your CSV to TSV and back for editing.
Toolkit for Text Generation and Beyond. Contribute to asyml/texar development by creating an account on GitHub.
TextBlob is a Python (2 and 3) library for processing textual data. It provides a simple API for diving into common natural language processing (NLP) tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more.
Features
- Noun phrase extraction
- Part-of-speech tagging
- Sentiment analysis
- Classification (Naive Bayes, Decision Tree)
- Language translation and detection powered by Google Translate
- Tokenization (splitting text into words and sentences)
- Word and phrase frequencies
- Parsing
- n-grams
- Word inflection (pluralization and singularization) and lemmatization
- Spelling correction
- Add new models or languages through extensions
- WordNet integration
Cat-like program with glitch animation.

glitchcat is a cat-like program with glitch animation.
