133 private links
Mathematicians regard the Collatz conjecture as a quagmire and warn each other to stay away. But now Terence Tao has made more progress than anyone in decades.

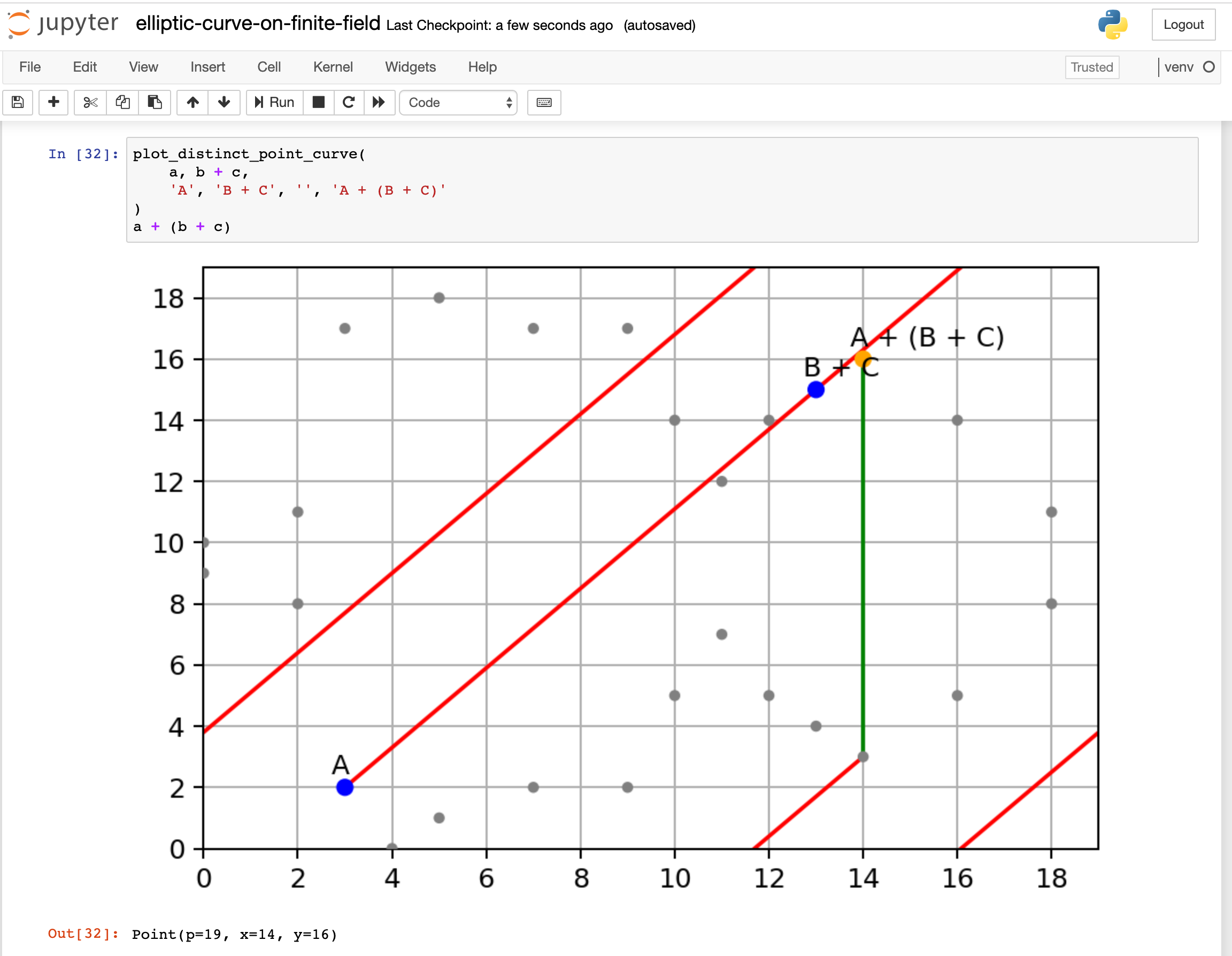
Recently, I am learning how Elliptic Curve Cryptography works. I searched around the internet, found so many articles and videos explaining it. Most of them are covering only a portion of it, some of them skip many critical steps how you get from here to there. In the end, I didn’t find an article that really explains it from end-to-end in an intuitive way.
With that in mind, I would like to write a post explaining Elliptic Curve Cryptography, cover from the basics to key exchange, encryption, and decryption.
The Dataverse Project - Dataverse.org
Can you spot a fake conference? It seems many researchers can’t. So here are 9 ways to spot a fake.
Summary
- The conference has an overly ambitious title
- The technical programme is broad. Very broad!
- The language on the conference website is… off
- Renowned organisations are sponsoring a low-profile conference
- The organisers’ contact details are missing, or aren’t quite right
- Another conference with a suspiciously similar name already exists
- The conference or its organisers have known associates
- The organisers are charging higher-than-normal fees
- The conference is unusually frequent
Clever tricks work around major hurdles, but it's not a route to high performance.
N-grams have been a common tool for information retrieval and machine learning applications for decades. In nearly all previous works, only a few values of $n$ are tested, with $n > 6$ being exceedingly rare. Larger values of $n$ are not tested due to computational burden or the fear of overfitting.
In this work, we present a method to find the top-$k$ most frequent $n$-grams that is 60$\times$ faster for small $n$, and can tackle large $n\geq1024$. Despite the unprecedented size of $n$ considered, we show how these features still have predictive ability for malware classification tasks. More important, large $n$-grams provide benefits in producing features that are interpretable by malware analysis, and can be used to create general purpose signatures compatible with industry standard tools like Yara. Furthermore, the counts of common $n$-grams in a file may be added as features to publicly available human-engineered features that rival efficacy of professionally-developed features when used to train gradient-boosted decision tree models on the EMBER dataset.
In a nutshell, it is a type of statistical model used for tagging abstract “topics” that occur in a collection of documents that best represents the information in them.
Many techniques are used to obtain topic models. This post aims to demonstrate the implementation of LDA: a widely used topic modeling technique.
Deep learning techniques have become the method of choice for researchers working on algorithmic aspects of recommender systems. With the strongly increased interest in machine learning in general, it has, as a result, become difficult to keep track of what represents the state-of-the-art at the moment, e.g., for top-n recommendation tasks. At the same time, several recent publications point out problems in today's research practice in applied machine learning, e.g., in terms of the reproducibility of the results or the choice of the baselines when proposing new models.
In this work, we report the results of a systematic analysis of algorithmic proposals for top-n recommendation tasks. Specifically, we considered 18 algorithms that were presented at top-level research conferences in the last years. Only 7 of them could be reproduced with reasonable effort. For these methods, it however turned out that 6 of them can often be outperformed with comparably simple heuristic methods, e.g., based on nearest-neighbor or graph-based techniques. The remaining one clearly outperformed the baselines but did not consistently outperform a well-tuned non-neural linear ranking method.
Overall, our work sheds light on a number of potential problems in today's machine learning scholarship and calls for improved scientific practices in this area. Source code of our experiments and full results are available at: https://github.com/MaurizioFD/RecSys2019_DeepLearning_Evaluation.
The outputs from scientific research are many and varied, including: research articles reporting new knowledge, data, reagents, and software; intellectual property; and highly trained young scientists. Funding agencies, institutions that employ scientists, and scientists themselves, all have a desire, and need, to assess the quality and impact of scientific outputs. It is thus imperative that scientific output is measured accurately and evaluated wisely.
Natural language processing algorithms applied to three million materials science abstracts uncover relationships between words, material compositions and properties, and predict potential new thermoelectric materials.
The overwhelming majority of scientific knowledge is published as text, which is difficult to analyse by either traditional statistical analysis or modern machine learning methods. By contrast, the main source of machine-interpretable data for the materials research community has come from structured property databases, which encompass only a small fraction of the knowledge present in the research literature. Beyond property values, publications contain valuable knowledge regarding the connections and relationships between data items as interpreted by the authors. To improve the identification and use of this knowledge, several studies have focused on the retrieval of information from scientific literature using supervised natural language processing, which requires large hand-labelled datasets for training. Here we show that materials science knowledge present in the published literature can be efficiently encoded as information-dense word embeddings (vector representations of words) without human labelling or supervision. Without any explicit insertion of chemical knowledge, these embeddings capture complex materials science concepts such as the underlying structure of the periodic table and structure–property relationships in materials. Furthermore, we demonstrate that an unsupervised method can recommend materials for functional applications several years before their discovery. This suggests that latent knowledge regarding future discoveries is to a large extent embedded in past publications. Our findings highlight the possibility of extracting knowledge and relationships from the massive body of scientific literature in a collective manner, and point towards a generalized approach to the mining of scientific literature.
We present HotStuff, a leader-based Byzantine fault-tolerant replication protocol for the partially synchronous model.
Once network communication becomes synchronous, HotStuff enables a correct leader to drive the protocol to consensus at the pace of actual (vs. maximum) network delay--a property called responsiveness--and with communication complexity that is linear in the number of replicas. To our knowledge, HotStuff is the first partially synchronous BFT replication protocol exhibiting these combined properties. HotStuff is built around a novel framework that forms a bridge between classical BFT foundations and blockchains. It allows the expression of other known protocols (DLS, PBFT, Tendermint, Casper), and ours, in a common framework.
Our deployment of HotStuff over a network with over 100 replicas achieves throughput and latency comparable to that of BFT-SMaRt, while enjoying linear communication footprint during leader failover (vs. quadratic with BFT-SMaRt).
In the midst of the deep learning hype, p-values might not be the hottest topic in data science. However, association mapping remains a fundamental tool to justify and underpin scientific conclusions. Inspired by an approach for time series classification based on predictive subsequences (i.e shapelets [1]), we developed S3M, a method that identifies short time series subsequences that are statistically associated with a class or phenotype while tackling the multiple hypothesis problem.
Daniel J. Bernstein, Bo-Yin Yang. "Fast constant-time gcd computation and modular inversion."
Lookup the rank of your conference.
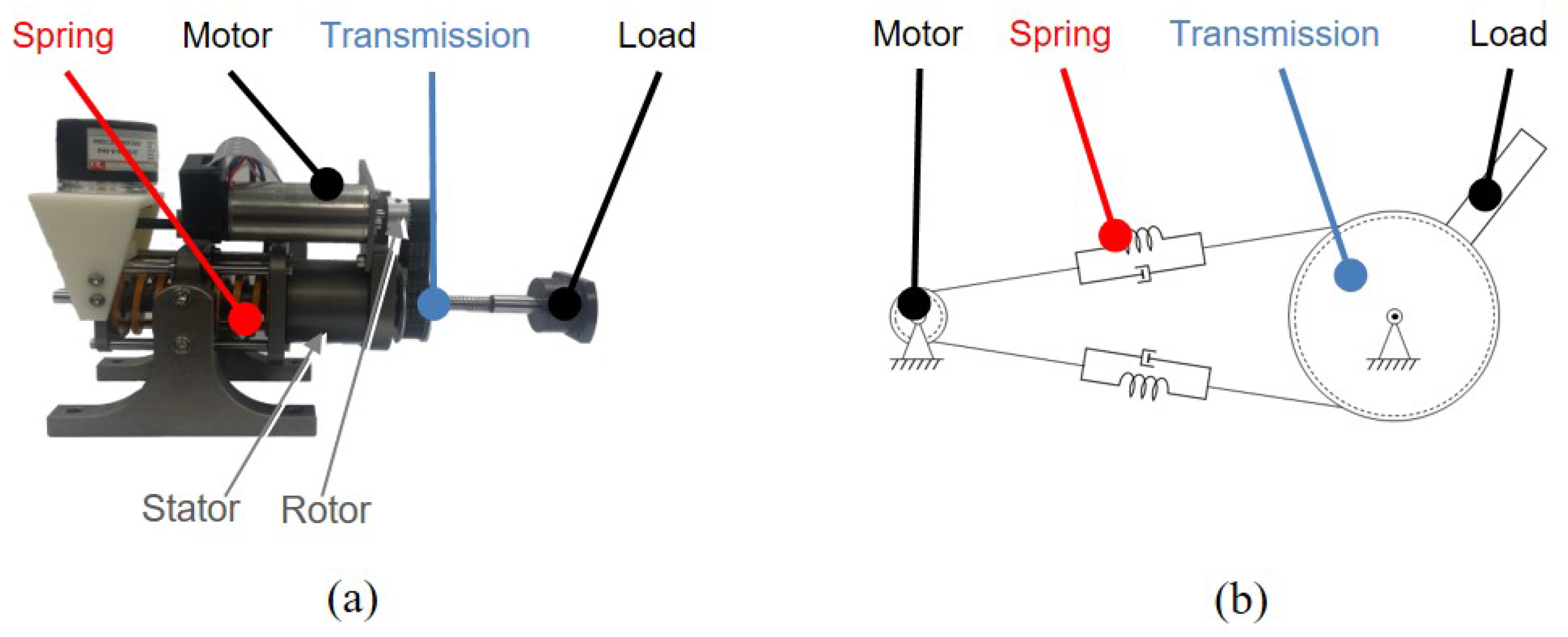
This video demonstrates the concept of series-elastic actuators (SEAs) and how they are used in rehabilitation robotics.

An old artifact kept in a vault outside Paris is no longer the standard for the kilogram. Now, nature itself provides the definition.
Developed in China, the lidar-based system can cut through city smog to resolve human-sized features at vast distances.
A new proof with important implications for game theory shows that no algorithm can possibly determine the winner.