133 private links
We are releasing HiPlot, a lightweight interactive visualization tool to help AI researchers discover correlations and patterns in high-dimensional data.

Clearview AI devised a groundbreaking facial recognition app. You take a picture of a person, upload it and get to see public photos of that person, along with links to where those photos appeared. The system — whose backbone is a database of more than three billion images that Clearview claims to have scraped from Facebook, YouTube, Venmo and millions of other websites — goes far beyond anything ever constructed by the United States government or Silicon Valley giants.
Facebook AI has developed the first neural network that uses symbolic reasoning to solve advanced mathematics problems.
Federal public comment websites currently are unable to detect Deepfake Text once submitted. I created a computer program (a bot) that generated and submitted 1,001 deepfake comments regarding a Medicaid reform waiver to a federal public comment website, stopping submission when these comments comprised more than half of all submitted comments. I then formally withdrew the bot comments.
Artificial intelligence bots have achieved superhuman results in zero-sum games such as chess, Go, and poker, in which each player tries to defeat the others. However, just like humans, real-world AI systems must learn to coordinate in cooperative environments as well.
To advance research on AI that can understand other points of view and collaborate effectively, Facebook AI has developed a bot that sets a new state of the art in Hanabi, a card game in which all players work together. Our bot not only improves upon previous AI systems but also exceeds the performance of elite human players, as judged by experienced players who have evaluated it.
This article discusses GPT-2 and BERT models, as well using knowledge distillation to create highly accurate models with fewer parameters than their teachers
What should worry us most about artificial intelligence: losing our jobs to cheaper labor or losing our lives to killer robots? The real threat may lie in yet another danger: losing our minds.
AI research is making great strides toward its long-term goal of human-level or superhuman intelligent machines. If it succeeds in its current form, however, that could well be catastrophic for the human race. The reason is that the “standard model” of AI requires machines to pursue a fixed objective specified by humans.
We are unable to specify the objective completely and correctly, nor can we anticipate or prevent the harms that machines pursuing an incorrect objective will create when operating on a global scale with superhuman capabilities. Already, we see examples such as social-media algorithms that learn to optimize click-through by manipulating human preferences, with disastrous consequences for democratic systems.
A new release from OpenAI shows how complex behavior emerges.
This week, leading AI lab OpenAI released their latest project: an AI that can play hide-and-seek. It’s the latest example of how, with current machine learning techniques, a very simple setup can produce shockingly sophisticated results.
Fake Text uses AI to analyze text and then generate incredibly detailed and realistic written responses to it, giving the impression that an exchange between humans is taking place. The AI analyses text patterns to put together disturbingly lucid text, typified by this Reddit thread.
Launched by leading global AI research lab OpenAI, Fake Text is already recognized as so potentially dangerous that even its inventors have publicly warned about it.
Check out a cool project that leverages Stack Overflow Data and Google's Cloud AI to predict what tags would work best on Stack Overflow questions.
This article focuses on using a Deep LSTM Neural Network architecture to provide multidimensional time series forecasting using Keras and Tensorflow - specifically on stock market datasets to provide momentum indicators of stock price.

The following article sections will briefly touch on LSTM neuron cells, give a toy example of predicting a sine wave then walk through the application to a stochastic time series. The article assumes a basic working knowledge of simple deep neural networks.

I recently wrote a Markov chain package which included a random text generator. The generated text is not very good.
The rest of this post covers the evolution of the main algorithm.
“Don’t think of the overwhelming majority of the impossible.”
“Grew up your bliss and the world.”
“what we would end create, creates the ground and you are the one to warm it”
“look and give up in miracles”
All the quotes above have been generated by a computer, using a program that consists of less than 20 lines of python code.
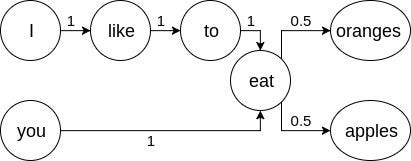
I originally wrote this paper in 1981 for a course in writing research papers at Rose-Hulman Institute of Technology. It was written on a DEC PDP-11/70 computer using the RUNOFF text formatting program, and having it on line from the beginning made it easy to save an electronic copy for future use. The instructor, Dr. Peter Parshall (of "Peter Parshall picked apart my perfect paper" fame), awarded the grade of A- to my work.
Part 1 of 2: "The Road to Superintelligence". Artificial Intelligence — the topic everyone in the world should be talking about.
Deep Learning has had a huge impact on computer science, making it possible to explore new frontiers of research and to develop amazingly useful products that millions of people use every day. Our internal deep learning infrastructure DistBelief, developed in 2011, has allowed Googlers to build ever larger neural networks and scale training to thousands of cores in our datacenters. We’ve used it to demonstrate that concepts like “cat” can be learned from unlabeled YouTube images, to improve speech recognition in the Google app by 25%, and to build image search in Google Photos. DistBelief also trained the Inception model that won Imagenet’s Large Scale Visual Recognition Challenge in 2014, and drove our experiments in automated image captioning as well as DeepDream.