133 private links

TextDistance, a python library for comparing distance between two or more sequences by many algorithms.
Features:
- 30+ algorithms
- Pure python implementation
- Simple usage
- More than two sequences comparing
- Some algorithms have more than one implementation in one class.
- Optional
numpyusage for maximum speed.
Python3 implementation of the Schwartz-Hearst algorithm for extracting abbreviation-definition pairs.
PCA is a linear dimensionality reduction technique. Many non-linear dimensionality reduction techniques exist, but linear methods are more mature, if more limited.
All Algorithms implemented in Python.
information theory, linguistics and computer science, the Levenshtein distance is a string metric for measuring the difference between two sequences. Informally, the Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions or substitutions) required to change one word into the other.
The images allow to easily, visually take in what a sorting algorithm did over time, as it took the list from an unsorted, random state to a completely sorted state. On the horizontal axis, we have a list of numbers, represented as a single line of colors. On the vertical axis, there is time. From the top of the image to the bottom of the image, there is the list of numbers (the line of colored pixels) from a random ordering to a “sorted” rainbow line, by applying each kind of sorting algorithm one step per row.
Solution for the Range Minimum Query problem with Sparse Tables and Dynamic Programming.
In this post we’ll explore how we can derive logistic regression from Bayes’ Theorem. Starting with Bayes’ Theorem we’ll work our way to computing the log odds of our problem and the arrive at the inverse logit function. After reading this post you’ll have a much stronger intuition for how logistic
Daniel J. Bernstein, Bo-Yin Yang. "Fast constant-time gcd computation and modular inversion."
A new proof with important implications for game theory shows that no algorithm can possibly determine the winner.
This is the 4th post in a series about migrating to functional programming. This week, I'll first implement the Dijkstra algorithm, then migrate the code to a more functional-friendly design. Dijkstra's algorithm allows to find the shortest path in any graph, weighted or not, directed or not. The only requirement is that weights must be positive.
Data structure and algorithms are core part of any Programming job interview. It doesn't matter whether you are a C++ developer, a Java developer or a Web developer working in JavaScript, Angular, React, or Query. As a computer science graduate, its expected from a programmer to have strong knowledge of both basic data structures e.g. array, linked list, binary tree, hash table, stack, queue and advanced data structures like the binary heap, trie, self-balanced tree, circular buffer etc. I have taken a lot of Java interviews for both junior and senior positions in the past, and I have been also involved in interviewing C++ developer. One difference which I have clearly noticed between a C++ and a Java developer is their understanding and command of Data structure and algorithms.
On average, a C or C++ developer showed a better understanding and application of data structure and their coding skill was also better than Java developers. This is not a coincidence though. As per my experience, there is a direct correlation between a programmer having a good command of the algorithm also happens to be a good developer and coder.
I firmly believe that interview teaches you a lot in very short time and that's why I am sharing some frequently asked Data structure and algorithm questions from various Java interviews.
If you are familiar with them than try to solve them by hand and if you do not then learn about them first, and then solve them. If you need to refresh your knowledge of data structure and algorithms then you can also take help from a good book our course like Data Structures and Algorithms: Deep Dive Using Java for quick reference.

![]()

![]()
Python sample codes for robotics algorithms.
Filtering, SLAM, path planning, kinematics.
![]()
A curated list of awesome Competitive Programming, Algorithm and Data Structure resources.
A library of common data structures and algorithms written in C.
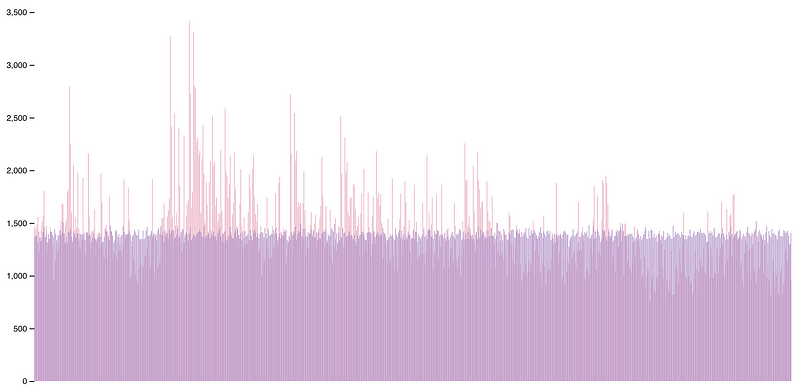
In “The Danger of Naïvete,” Jeff Atwood explains that the reason the naive shuffle algorithm is biased (and fundamentally broken) is because it overshuffles the cards in the deck by selecting each card’s swap from the entire deck every time. This means that some cards are getting moved multiple times!
The image shows naive shuffle vs. Fisher-Yates shuffle, 1 million tries on a 6-item set. On the X axis there are the different possible final combinations, while the Y axis reports the count for each combination.