122 private links
Google Colaboratory Notebooks and Repositories.

Artificial intelligence bots have achieved superhuman results in zero-sum games such as chess, Go, and poker, in which each player tries to defeat the others. However, just like humans, real-world AI systems must learn to coordinate in cooperative environments as well.
To advance research on AI that can understand other points of view and collaborate effectively, Facebook AI has developed a bot that sets a new state of the art in Hanabi, a card game in which all players work together. Our bot not only improves upon previous AI systems but also exceeds the performance of elite human players, as judged by experienced players who have evaluated it.
This article will provide the reader with a brief overview for a number of different Linux commands. A special emphasis will be placed on explaining how each command can be used in the context of performing data science tasks. The goal will be to convince the reader that each of these commands can be extremely useful, and to allow them to understand what role each command can play when manipulating or analyzing data.
This post overviews the paper Confident Learning: Estimating Uncertainty in Dataset Labels authored by Curtis G. Northcutt, Lu Jiang, and Isaac L. Chuang.
This article discusses GPT-2 and BERT models, as well using knowledge distillation to create highly accurate models with fewer parameters than their teachers
This recent Tweet erupted a discussion about how logistic regression in Scikit-learn uses L2 penalization with a lambda of 1 as default options. If you don’t care about data science, this sou…
Learn how to use the k-means clustering algorithm to segment data.
Python3 implementation of the Schwartz-Hearst algorithm for extracting abbreviation-definition pairs.
Millions of Flickr images were sucked into a database called MegaFace. Now some of those faces may have the ability to sue.

Streamlit is the first app framework specifically for Machine Learning and Data Science teams.
So you can stop spending time on frontend development and get back to what you do best.
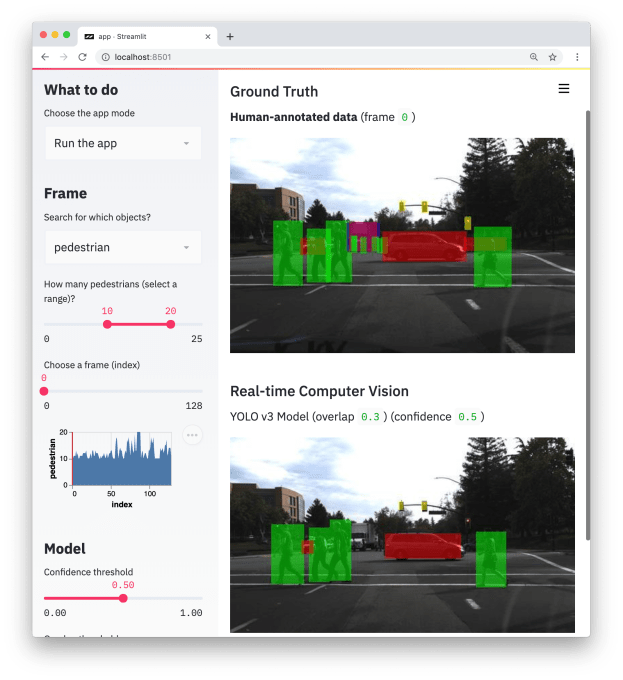
Introducing Streamlit, an app framework built for ML engineers.
Reinforcement learning refers to goal-oriented algorithms, which learn how to attain a complex objective (goal) or maximize along a particular dimension over many steps.
Bayes Theorem provides a principled way for calculating a conditional probability. It is a deceptively simple calculation, although it can be used to easily calculate the conditional probability of events where intuition often fails. Bayes Theorem also provides a way for thinking about the evaluation and selection of different models for a given dataset in …
GitHub announces the CodeSearchNet Challenge and releasing a large dataset for natural language processing and machine learning.
AutoOut is an automated outlier detection and treatment tool that allows you to get better models with even better accuracy without writing a single line of code. With it's easy to use and simple interface you can detect and treat outliers in your dataset, that can help improve your final model.
Computers are taking the error out of human chess — and the adventure.
A Machine Learning System for Data Enrichment.
TOM (TOpic Modeling) is a Python 3 library for topic modeling and browsing, licensed under the MIT license.
Its objective is to allow for an efficient analysis of a text corpus from start to finish, via the discovery of latent topics. To this end, TOM features functions for preparing and vectorizing a text corpus. It also offers a common interface for two topic models (namely LDA using either variational inference or Gibbs sampling, and NMF using alternating least-square with a projected gradient method), and implements three state-of-the-art methods for estimating the optimal number of topics to model a corpus. What is more, TOM constructs an interactive Web-based browser that makes it easy to explore a topic model and the related corpus.